Ознакомьтесь с Условиями пребывания на сайте Форнит Игнорирование означет безусловное согласие. СОГЛАСЕН
Книги сайта: «Мировоззрение»,
«Познай себя» , «Основы адаптологии» ,
Фантазмы , Лекторий МВАП , «Что такое Я» , «Наука», «Субъективность».
Чтобы оставлять сообщения нужно авторизоваться.
Тема форума: «Бот на ГО»
| Сообщений: 605 Просмотров: 43192 | | Вся тема для печати |
Это тема – только для причастных к пониманию модели МВАП и текущим проблемам предметной области «Схемотехника адаптивных нейросетей». Прошу посторонним быть очень корректным и зря не спамить. Здесь будет обсуждаться текущая реализация последовательности развития прототипа индивидуальной системы адаптивности Beast.
Телеграм-канал: https://t.me/thinking_cycles
nan - админ
- админ Род:  Сообщений: 12298 личная фото-галерея  Оценок: 39 Оценок: 39список всех сообщений clons Сообщение № 47236 показать отдельно Январь 24, 2021, 04:53:45 PM ответ -только после авторизации | |||||||||
p.s. Допускаю, что мое утверждение может быть неверно, поэтому прошу показывать, что именно и почему неверно и запрашивать объяснения, если что-то непонятно. Метка админа: | |||||||||
|
Palarm
- админ Род: Сообщений: 2771 личная фото-галерея Оценок: 6список всех сообщений clons Сообщение № 47237 показать отдельно Январь 24, 2021, 07:00:26 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
Palarm
- админ Род: Сообщений: 2771 личная фото-галерея Оценок: 6список всех сообщений clons Сообщение № 47242 показать отдельно Январь 25, 2021, 04:56:27 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
nan
- админ Род: Сообщений: 12298 личная фото-галерея Оценок: 39список всех сообщений clons Сообщение № 47243 показать отдельно Январь 25, 2021, 05:27:00 PM ответ -только после авторизации | |||||||||
p.s. Допускаю, что мое утверждение может быть неверно, поэтому прошу показывать, что именно и почему неверно и запрашивать объяснения, если что-то непонятно. Метка админа: | |||||||||
|
Palarm
- админ Род: Сообщений: 2771 личная фото-галерея Оценок: 6список всех сообщений clons Сообщение № 47244 показать отдельно Январь 25, 2021, 06:03:39 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
nan
- админ Род: Сообщений: 12298 личная фото-галерея Оценок: 39список всех сообщений clons Сообщение № 47245 показать отдельно Январь 25, 2021, 07:50:35 PM ответ -только после авторизации | |||||||||
p.s. Допускаю, что мое утверждение может быть неверно, поэтому прошу показывать, что именно и почему неверно и запрашивать объяснения, если что-то непонятно. Метка админа: | |||||||||
|
Palarm
- админ Род: Сообщений: 2771 личная фото-галерея Оценок: 6список всех сообщений clons Сообщение № 47247 показать отдельно Январь 26, 2021, 10:27:04 AM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||

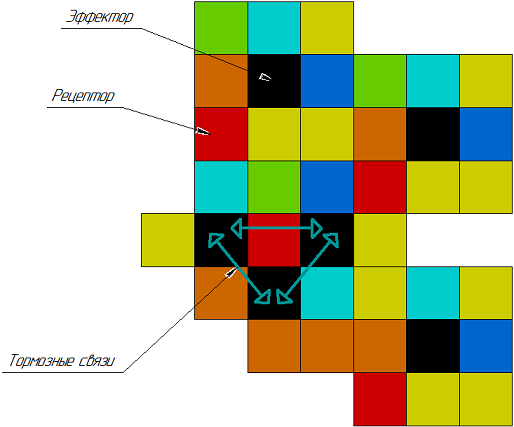
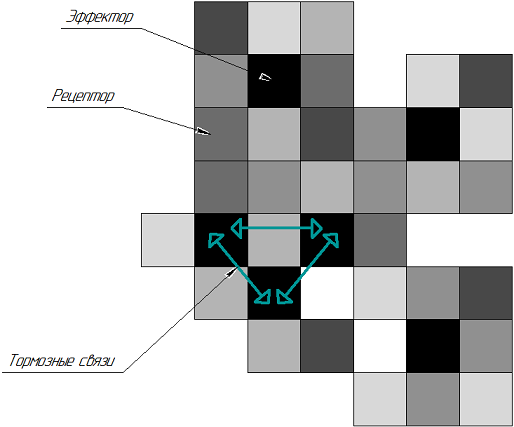
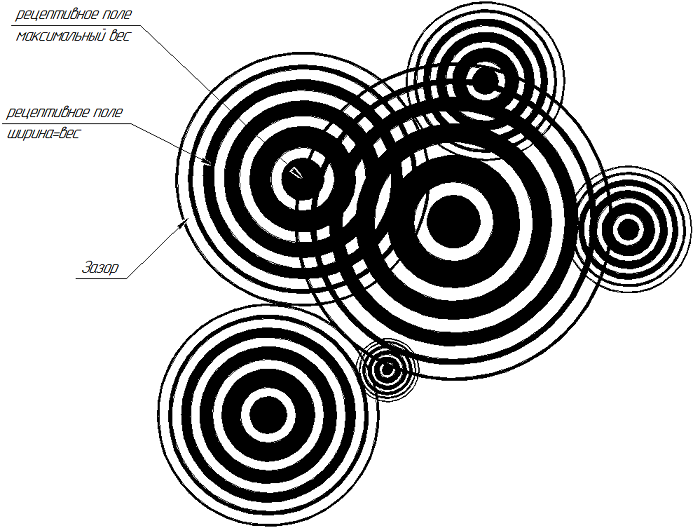
|
Palarm
- админ Род: Сообщений: 2771 личная фото-галерея Оценок: 6список всех сообщений clons Сообщение № 47248 показать отдельно Январь 26, 2021, 10:52:20 AM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
Palarm
- админ Род: Сообщений: 2771 личная фото-галерея Оценок: 6список всех сообщений clons Сообщение № 47251 показать отдельно Январь 29, 2021, 01:29:41 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
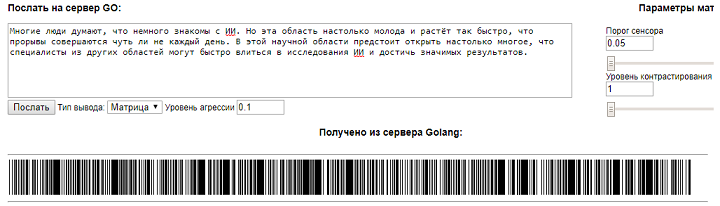
|
nan
- админ Род: Сообщений: 12298 личная фото-галерея Оценок: 39список всех сообщений clons Сообщение № 47252 показать отдельно Январь 29, 2021, 01:51:27 PM ответ -только после авторизации | |||||||||
p.s. Допускаю, что мое утверждение может быть неверно, поэтому прошу показывать, что именно и почему неверно и запрашивать объяснения, если что-то непонятно. Метка админа: | |||||||||
|
Palarm
- админ Род: Сообщений: 2771 личная фото-галерея Оценок: 6список всех сообщений clons Сообщение № 47253 показать отдельно Январь 30, 2021, 04:50:14 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||

|
nan
- админ Род: Сообщений: 12298 личная фото-галерея Оценок: 39список всех сообщений clons Сообщение № 47254 показать отдельно Январь 31, 2021, 02:38:37 PM ответ -только после авторизации | |||||||||
p.s. Допускаю, что мое утверждение может быть неверно, поэтому прошу показывать, что именно и почему неверно и запрашивать объяснения, если что-то непонятно. Метка админа: | |||||||||
|
Palarm
- админ Род: Сообщений: 2771 личная фото-галерея Оценок: 6список всех сообщений clons Сообщение № 47255 показать отдельно Январь 31, 2021, 05:10:24 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
Palarm
- админ Род: Сообщений: 2771 личная фото-галерея Оценок: 6список всех сообщений clons Сообщение № 47256 показать отдельно Февраль 01, 2021, 08:27:33 AM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
|
Palarm
- админ Род: Сообщений: 2771 личная фото-галерея Оценок: 6список всех сообщений clons История редактирования (1)
Сообщение № 47257 показать отдельно Февраль 01, 2021, 12:14:40 PM ответ -только после авторизации | |||||||||
Метка админа: | |||||||||
Всего Тем: 1928 Всего Сообщений: 47875 Всего Участников: 5219 Последний зарегистрировавшийся: Geo
Страница статистики форума | Список пользователей | Список анлимитов
Последняя из новостей:
Страница статистики форума | Список пользователей | Список анлимитов
Эгоцентризм – основа субъективности. Когда механизм становится переживанием? Две половинки мозга и одна субъективность: Формирование субъективного опыта в онтогенезе.
Пользователи на форуме:| Обнаружен организм с крупнейшим геномом Новокаледонский вид вилочного папоротника Tmesipteris oblanceolata, произрастающий в Новой Каледонии, имеет геном размером 160,45 гигапары, что более чем в 50 раз превышает размер генома человека. | Тематическая статья: Формирование субъективного опыта в онтогенезе |
Рецензия: Работы А.Иваницкого, комментарии | Топик ТК: Свойства осознанного внимания и циклы |
| Из коллекции изречений: >>показать еще... |